#include <iostream> using namespace std; int main(){ int n = 123,m = 456; int *p = &n; cout<<"&n:"<<&n<<endl; cout<<"&p:"<<&p<<endl; cout<<" p:"<<p<<endl; cout<<"*p:"<<*p<<endl; return 0; }
&:取地址运算符。返回变量对应的存储单元地址,若a为int变量,p为int型指针变量,则 p = &a表示将a的存储单元地址赋给p。 用一个程序验证一下:
1 2 3 4 5 6 7 8 9 10 11 12 13
#include <iostream> using namespace std; int main(){ int a = 100; int *p,*p1,*q; p = &a; p1 = p; q = NULL; cout<<"a="<<a<<","<<"*p="<<*p<<","<<"p="<<p<<endl; *p1 = 200; cout<<"a="<<a<<","<<"*p="<<*p<<","<<"p="<<p<<endl; cout<<"*p1="<<*p1<<","<<"p1="<<p1<<endl; }
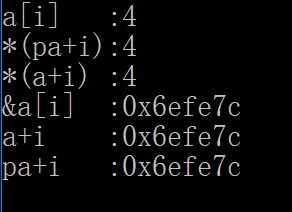
#include <iostream> using namespace std; int main(){ int a[10]={1,2,3,4,5,6,7,8,9,10}; int *pa = a; int i = 3; cout<<"a[i] :"<<a[i]<<endl; cout<<"*(pa+i):"<<*(pa+i)<<endl; cout<<"*(a+i) :"<<*(a+i)<<endl; cout<<"&a[i] :"<<&a[i]<<endl; cout<<"a+i :"<<a+i<<endl; cout<<"pa+i :"<<pa+i<<endl; }
#include <iostream> using namespace std; int cul(int (*pf)(int,int), int x, int y){ return pf(x,y); } int add(int x,int y){ return x+y; } int sub(int x,int y){ return x-y; } int main(){ int a=10,b=20; cout<<a<<"+"<<b<<"="<<cul(add,a,b)<<endl; cout<<a<<"-"<<b<<"="<<cul(sub,a,b); }
import scrapy class IproxyItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() ip = scrapy.Field() type = scrapy.Field() port = scrapy.Field()
爬取所有的免费ip
在spider目录下,创建IpSpider.py
1 2 3 4 5 6 7 8 9 10 11 12 13
import scrapy import Iproxy.items class IpSpider(scrapy.Spider): name = 'IpSpider' allowed_domains = ['xicidaili.com'] start_urls = ['http://www.xicidaili.com/']
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql import requests
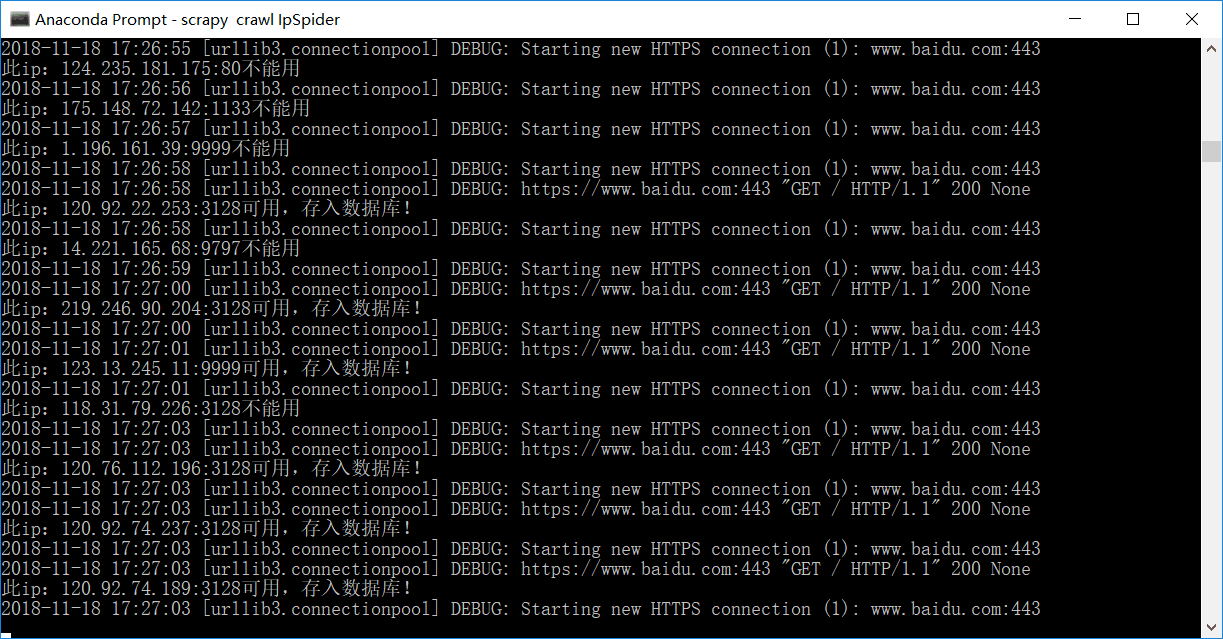
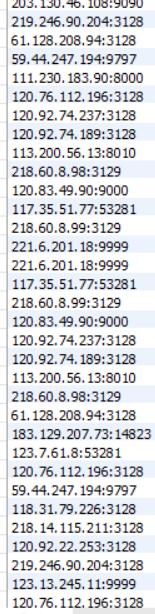
class IproxyPipeline(object): def process_item(self, item, spider): print('@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@') db = pymysql.connect("localhost", "root", "168168", "spider") cursor = db.cursor() for i in range(1, len(item['ip'])): ip = item['ip'][i] + ':' + item['port'][i] try: if self.proxyIpCheck(ip) is False: print('此ip:'+ip+"不能用") continue else: print('此ip:'+ip+'可用,存入数据库!') sql = 'insert into proxyIp value ("%s")' % (ip) cursor.execute(sql) db.commit() except: db.rollback() db.close() return item
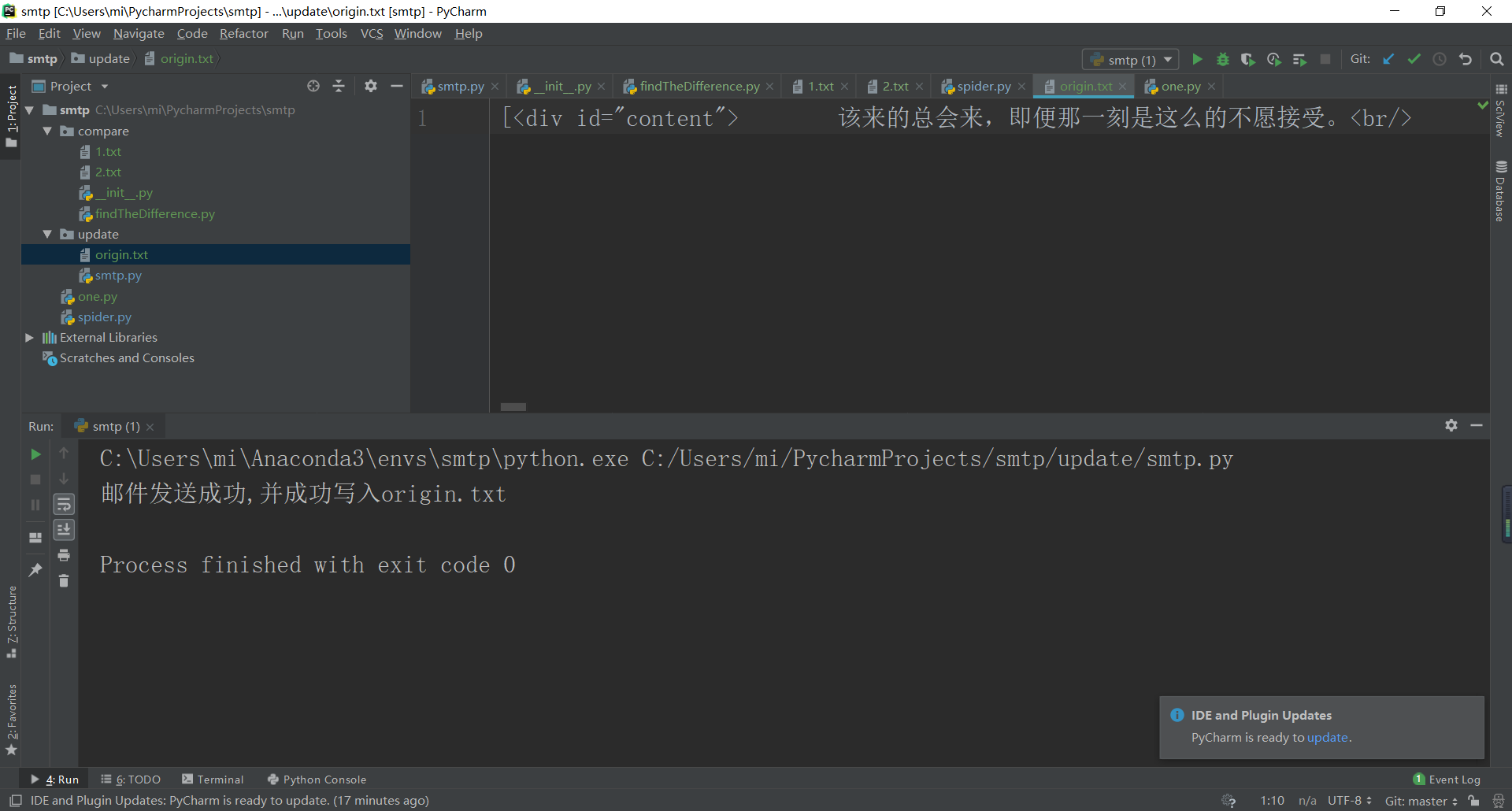
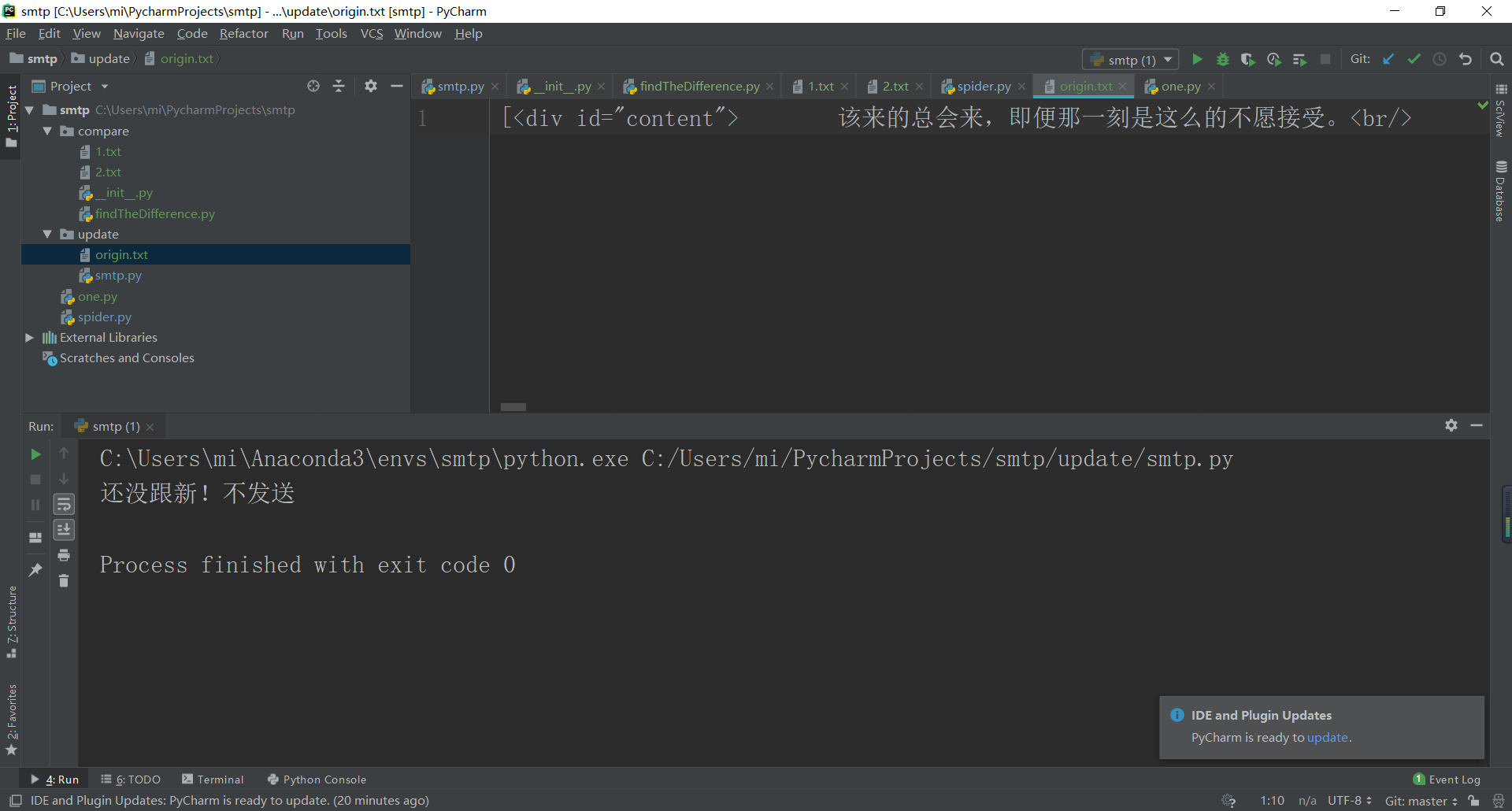
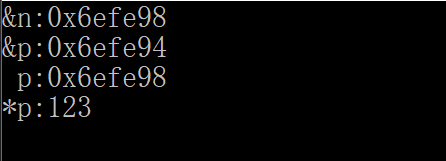

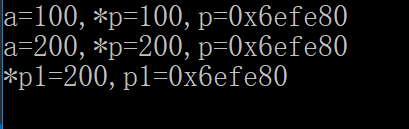
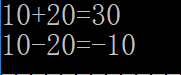
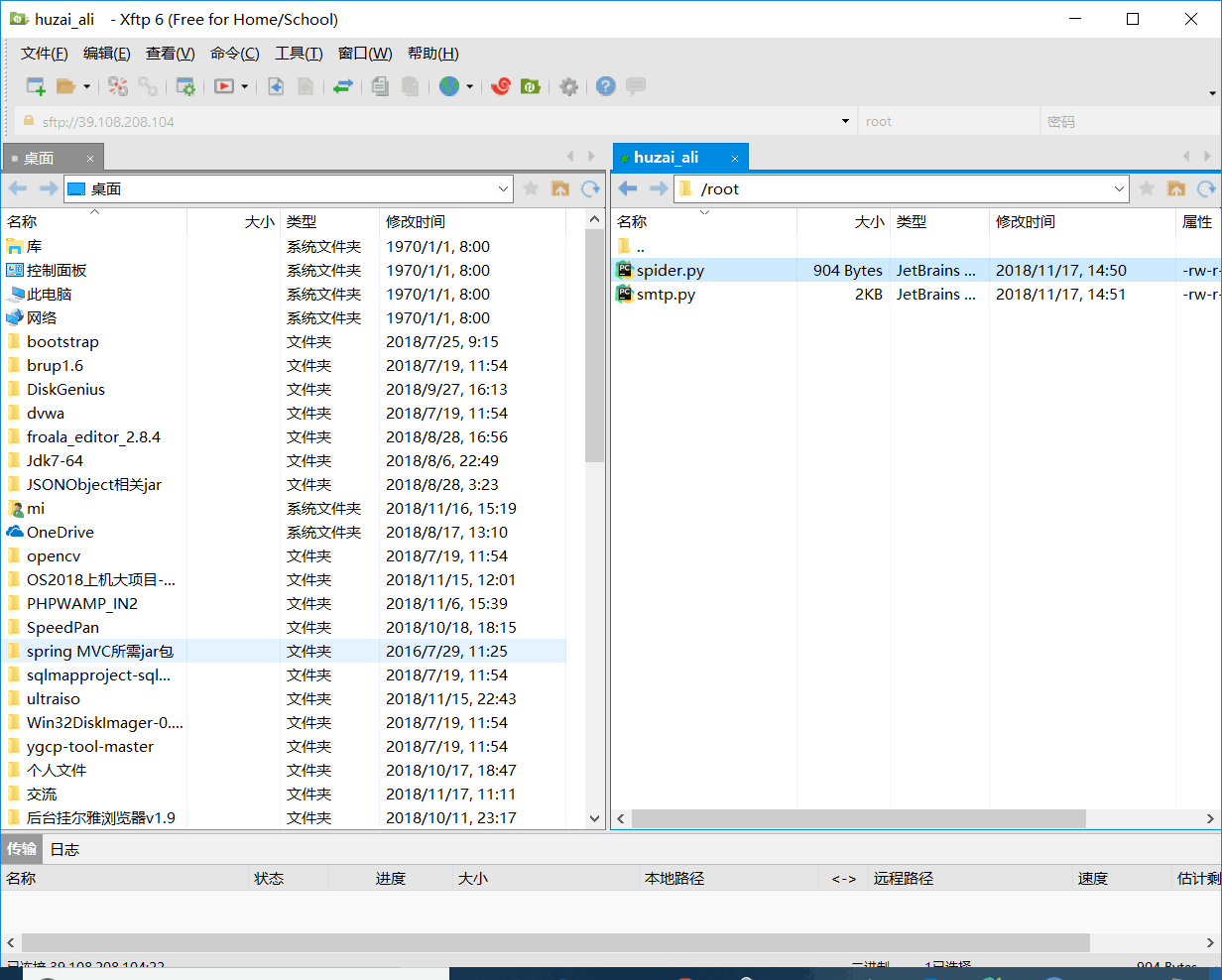



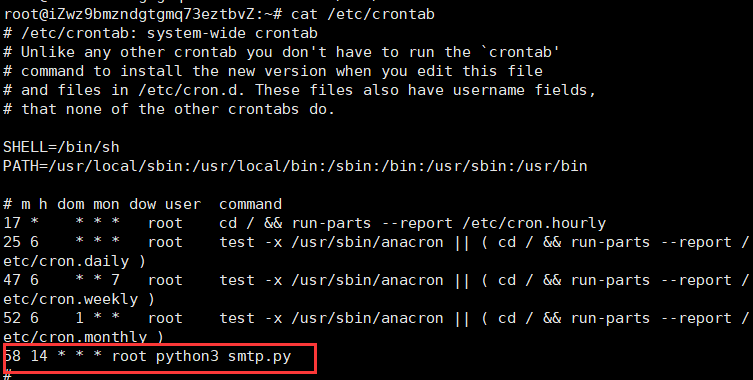
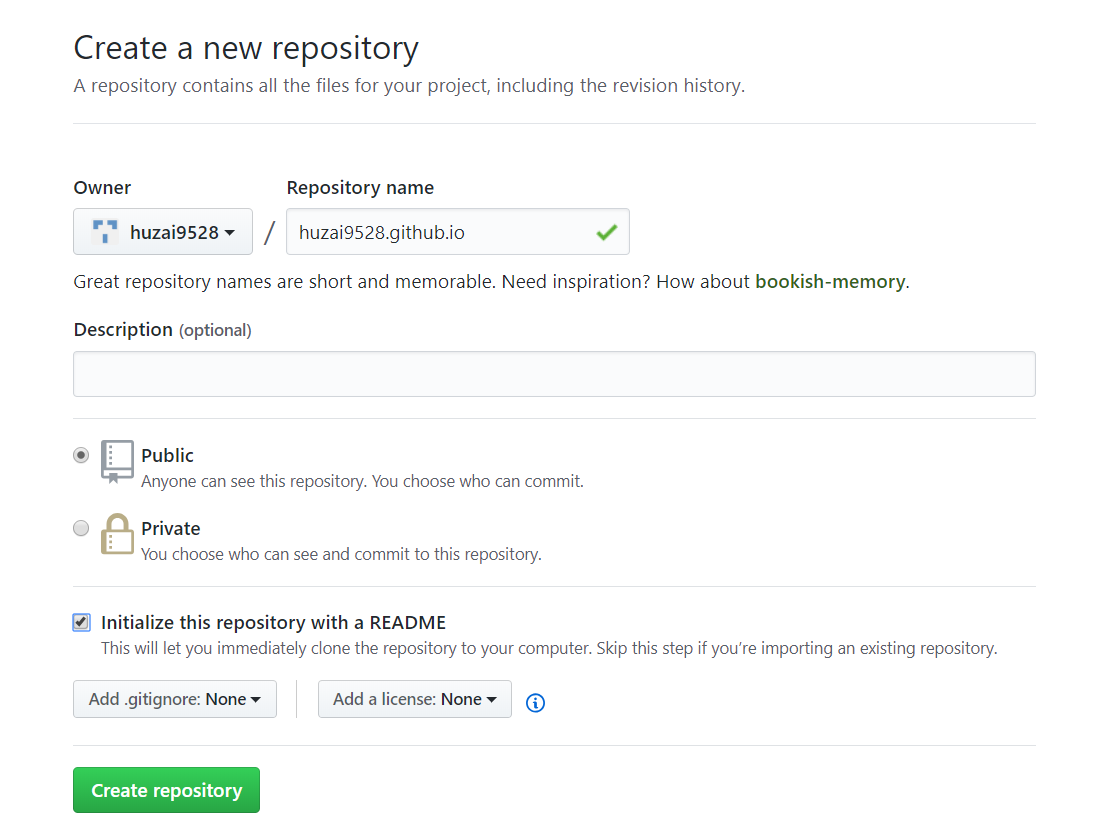


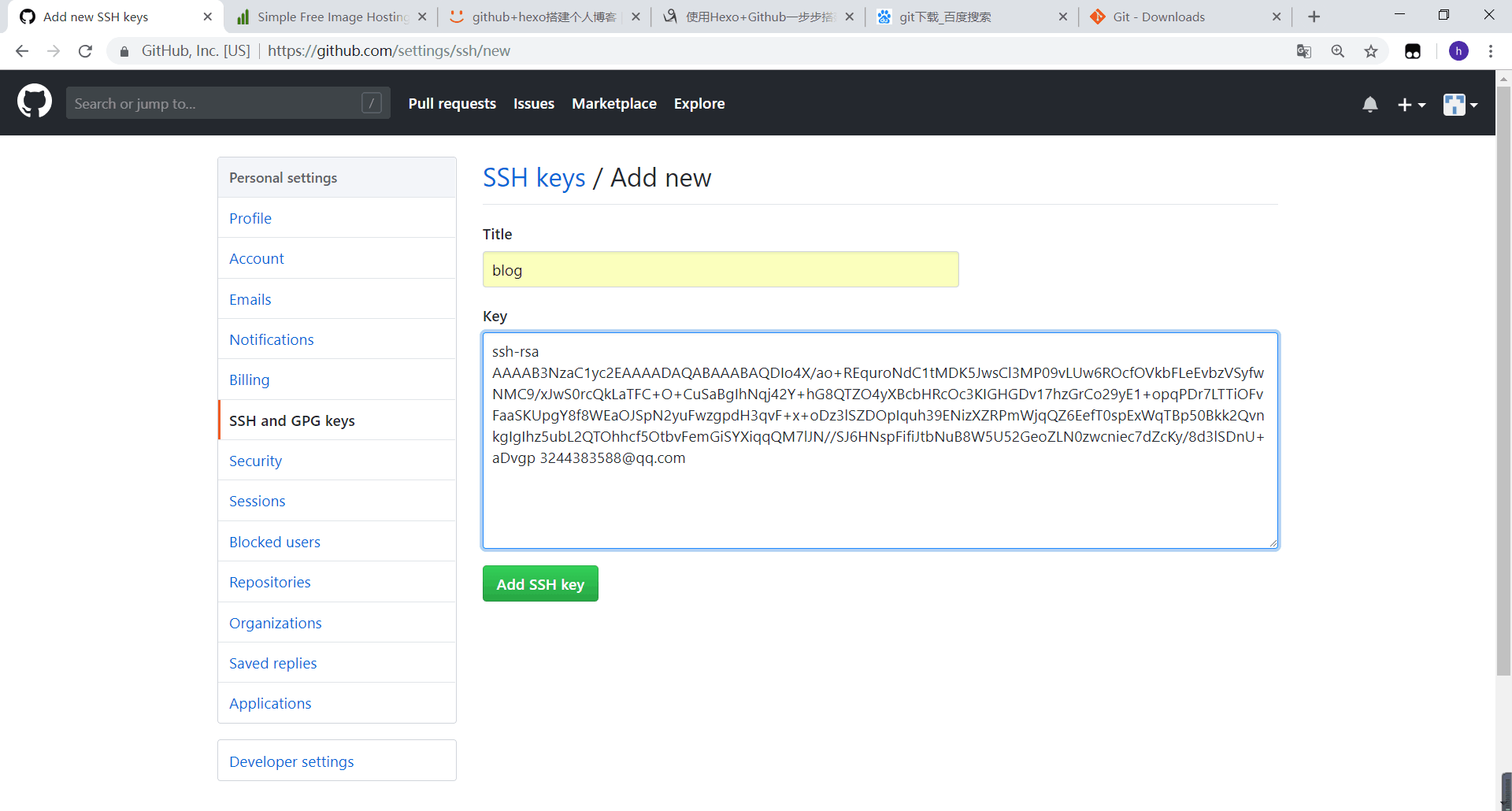

 这样就算上传成功
这样就算上传成功